
 |
 |
 |
|
 |
The following is a relatively long overview of how human language works. It comprises definitions that will be useful for understanding terms used and some statements made in the next pages. For its largest part, it is a summary of conventional terminology used in communication theory and (mainly) linguistics. When the terminology is not (or diverges from the) conventional, this is for reasons of convenience (as in "making our lives easier"). The rest represents my personal ideas and opinions and should be read bearing in mind that I am not an authority on these subjects.
Since the following analysis is rather long and cumbersome and is not directly related to the study of Greek, this page can be skipped and its relevant parts consulted only through the links provided on the other pages.
Considered in the context of communication systems, human language is the means for transferring abstract (as in "intangible") concepts from one human brain to another. These concepts are expressed by words. To transfer the words from one human being ("transmitter") to another ("receiver"), they are converted to "signals" over either of two "transmission media":
 |
Thus, human language exists in two "modes", SPEECH and WRITING, respectively for each of the above transmission media. In order to adapt the words in a form suitable for a transmission medium, human "transmitters" use "modulators"; in the case of speech, the modulator is provided by the vocal system, which comprises the mouth (including the oral cavity and the tongue), as well as the nasal cavity and the vocal chords, powered by air from the lungs; in the case of writing, the modulator is typically provided by the hands that act on objects (paper, stone, etc) to produce the visual markings (images, letters, etc), usually aided by tools (pen, chisel, keyboard, etc). On the other side, human "receivers" perceive these signals by means of "demodulators", typically the ear for speech and the eye for writing.
| Mode | Medium | Signal | Modulator | Demodulator |
|---|---|---|---|---|
| Speech | air | air waves | mouth | ear |
| Writing | physical objects | visual markings | hands | eye |
On one hand, the human demodulator is far from perfect and non-standardised (different persons perceive the same sound differently), so that slight differences between two sound waveforms cannot be easily perceived. On the other hand, voice communication is usually performed in noisy environments and the transmitted waveform is distorted in various degrees, so that the received waveform differs from the transmitted. In (tele)communication theory, this problem is addressed by employing a so-called "digital-communication model", wherein out of the continuum of all possible (analogue) waveforms a small set of discrete waveforms ("symbols") is selected and only these can be transmitted; the demodulator can, thus, identify any distorted received waveform as one of the few candidates even with a reasonable amount of distortion.
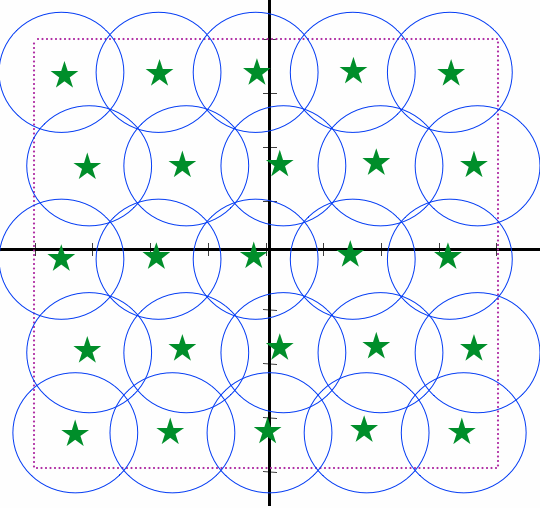 In "digital-communication
model" nomenclature, the space (continuum) of
all possible waveforms is "quantised"
(partitioned) into regions around the selected
symbols. In fact, what is "quantised" is a set of properties and how
much of each of the properties the waveform comprises. In the example
illustrated to the left, each waveform is assumed to comprise an amount
of two properties (e.g., sine and cosine, frequency A and frequency B,
basic waveform A and basic waveform B) represented by the two
perpendicular axes. The green stars are the "symbols" selected as
representative waveforms and the blue circles approximately represent
the "region" of received waveforms that are "perceived" as the symbol
in the center. It is evident that the finer the quantisation (i.e., the
more symbols are
defined), the higher the likelihood that a distortion will make a
received symbol "look" closer to (and, hence, be perceived as) a symbol
different from the one transmitted (since the symbols will be closer to
each other). There is, therefore, a compromise
between the number of
symbols and the robustness of the quantisation scheme.
In "digital-communication
model" nomenclature, the space (continuum) of
all possible waveforms is "quantised"
(partitioned) into regions around the selected
symbols. In fact, what is "quantised" is a set of properties and how
much of each of the properties the waveform comprises. In the example
illustrated to the left, each waveform is assumed to comprise an amount
of two properties (e.g., sine and cosine, frequency A and frequency B,
basic waveform A and basic waveform B) represented by the two
perpendicular axes. The green stars are the "symbols" selected as
representative waveforms and the blue circles approximately represent
the "region" of received waveforms that are "perceived" as the symbol
in the center. It is evident that the finer the quantisation (i.e., the
more symbols are
defined), the higher the likelihood that a distortion will make a
received symbol "look" closer to (and, hence, be perceived as) a symbol
different from the one transmitted (since the symbols will be closer to
each other). There is, therefore, a compromise
between the number of
symbols and the robustness of the quantisation scheme.
There is a lot of confusion in linguistics, about the elements of speech. A continuous sequence of utterances can be generally broken down into parts (of variable duration), in which the sound is substantially "uniform" (that is, it does not change). The Greek term applied to these sounds is "φθόγγος", a term that exists in English only as the second constituent of the compounds "monophthong", "diphthong" etc. The linguistic term used in English is "phone", which however causes some confusion when applied to Greek phonology, because it corresponds to a transliteration of the Greek word "φωνή", that is "voice", which is the very notion we are trying to analyse (break down into a series of elementary sounds). A more appropriate term is "phoneme", which comes from Greek "φώνημα", uttered sound. However, linguists use this term to refer to a "family of related sounds": a sound that is perceived as "the same" by native speakers of a language may be pronounced slightly differently in different contexts of continuous speech (that is, with different other sounds around it); the typical example provided in English is the difference in pronunciation of "p" , "t", "k" in the words "pill", "till", "kill" (aspirated at the beginning of a word) and "spill", "still", "skill" (normal or unaspirated in the middle of the word), the two slightly different pronunciations ([pʰ], [tʰ], [kʰ] and [p], [t], [k] in IPA notation) are called allophones" of the same phoneme (/p/, /t/, /k/ in IPA notation). In addition to being too technical, this definition of a "phoneme" may lead to a confusion between letters and (their) sounds (in the aforementioned example, one may be led to consider the letters "p" , "t", "k" as "phonemes" and their pronunciation in each context as "phones", which would be incorrect), so it will be avoided (note that we have not discussed "letters" yet).
In seeking an appropriate term for expressing the concept of "φθόγγος", we cannot use the inapt term "phthong" (it does not exist as such in English) nor the linguistically-correct term "phone" (which alludes to the very subject of analysis, voice). The term "phonemes", which is etymologically closer, will therefore be used to describe the basic elements of speech, the "φθόγγοι|plural of φθόγγος".
The symbols of the digital-communication model correspond to "phonemes" in the case of speech. Although, strictly speaking, the phonemes are analog waveforms, they are characterised by a small set of "properties", which relate to the way each phoneme has to be pronounced and, more specifically, to the modification of the organs of the vocal system (lips, tongue, vocal chords, etc.) necessary for the production of the corresponding sound.
There are two main types of phonemes: "vowels" and "consonants". Other kinds of phonemes, such as "semivowels" and some exotic sounds, are not of interest for the study of Greek and will not be mentioned here.
Vowels are characterised by how they are articulated. The two main properties related to articulation are:
The term "diphthong", although it actually means "dual sound", only applies to vowels. It refers to two vowels "spoken together", "one after the other without a pause", "in one breath", "with a glide from one to the other" or whatever one thinks that describes a sound that initially resembles one vowel but finally another. Effectively, it sounds as if one changed one's mind midway through the articulation about what vowel to pronounce. English is infested with diphthongs, but in Greek there are but a few cases where two vowels have to be pronounced as a diphthong.
The concept behind diphthongs (combination of the sound of two vowels) can be extended to "triphthongs" (combination of the sound of three vowels), which exist in some languages including English, but not in Greek, as far as I can tell. We will, thus, only consider diphthongs and "monophthongs", that is single vowels.
It is generally difficult to provide a precise definition of a what is a "word"; usually the definition is language-specific: what in one language is considered as one word, in another it may be considered two or more. As an example, the Spanish word "dámelo"[SPA] translates into English literally as "give me it" (three words) and more correctly as "give it to me" (four words). The definition of what is a "word" is also problematic within the context of the same language, as evidenced by "dámelo"[SPA] above. As an English example, "birthday" is considered as a single word (more precisely a compound word) in English, but this is pure convention, since it would make perfect sense even if it were considered to represent two words: "birth day" (making the first word a noun adjunct). A further example of this kind is "ball boy", which conventionally is considered two words, but it may also appear as one. This confusion is usually the result of writing conventions, where words are separated by spaces. In view of the above, a more precise definition of what is a "word" will not be attempted.
In general, in order to build a compound word, one has to place its two constituents one next to the other. This works best in English: "fire"+"fighter"=firefighter, "space"+"man"="spaceman", etc. In some languages, the first constituent may undergo some kind of transformation and some epenthetic elements may be added. These two phenomena are illustrated in the English word of Greek origin "arachnophobia", which is analysed as "arachne|spider" - "e" + "o" + "phobia|fear [of]", wherein the first constituent ("arachne") loses its ending ("e") and "o" is the epenthetic element. The insertion of epenthetic elements is also typical in German (the German term "Fugenelemente|seaming elements"[GER] being more descriptive), where the word "Liebeslied|love song"[GER] is analysed as "Liebe|love"[GER] + "s" + "Lied|song"[GER], wherein "s" is the epenthetic element (note, however, that it is not universal in German, as exemplified by "Haftpflichtversicherung|liability insurance"[GER], which is analysed as "Haftpflicht|liability (itself a compound word in German)"[GER] + "Versicherung|insurance"[GER] ).
Although the building elements of words are the individual sounds, the phonemes, their actual building blocks are the "syllables". This is evidenced by the fact that, when repeating more clearly a word that has not been understood the first time, it is more natural to recite the syllables (to syllabify): "ba-na-na", rather than the individual sounds: "b-a-n-a-n-a".I mean [b]-[ə]-[n]-[a]-[n]-[ə], not [bi:]-[eɪ]-[bi:]-[eɪ]-[ɛn]-[eɪ]
It may be, thus, argued that syllables and phonemes are to speech as atoms (more precisely ions) and subatomic particles (protons, neutrons, electrons) are to matter. To use a more precise metaphor, vowels are like protons and consonants are like neutrons and/or electrons.In order for the metaphor to work, one has to, unrealistically, assume that there are more than one kind of protons and more than one kind of neutrons and/or electrons. No atom can exist without at least one proton and no neutron or electron can form an atom by itself (whereas a single proton can form an atom, better a cation). Although neutrons and electrons can be artificially isolated, matter comprises those only as embedded in atoms.
Similarly, a syllable may comprise as few as one vowel, but it may never comprise only consonants. A syllable may comprise two vowels only when those form a diphthong. In conclusion, a syllable typically comprises a single vowel and some of its surrounding consonants. Some languages have taken the definition of syllable beyond the limitations of the aforementioned paradigm, but we will not be concerned with those. Our model for a syllable will, therefore, be:
CVC
wherein each of C and C consists of zero or more consonants and V is exactly one vowel (monophthong) or diphthong. The phonemes forming a word can be grouped into syllables of the above type and each word comprises one or more syllables, their number being equal to the number of monophthongs and diphthongs. Many words in English are monosyllabic, but the majority of words in languages like Greek are polysyllabic. Polysyllabicity contributes to redundancy and hence robustness, since it defers the differentiation between words from the number of possible phonemes to the number of the word's syllables (in order to differentiate between monosyllabic words, a higher number of phonemes is usually required).cf. tan, ten, tin, ton, tun, tine, tone, tune, teen, toon, town.
In most languages, at least one of the syllables of a polysyllabic word is pronounced in a way different from the others: it is emphasised or "stressed" or "accented". The most common form of stress or accentuation is the "dynamic accent", where the accented syllable is pronounced somewhat louder than the rest. Dynamic accent is almost omnipresent in European languages, including English and Greek. In some languages, such as Spanish and Greek, each polysyllabic word has exactly one accent (cf. "alimentación"[SPA]). Others however, such as English, find it difficult to have more than two or three unaccented syllables in a row and, in addition to the "primary accent", they make use of "secondary accents".cf. "alimentation" pronounced as "ˌaləmenˈtāshən"; note the primary " ˈ " and secondary " ˌ " accents. German also has multiple accents in polysyllabic words, but this is usually the result of each constituent of a compound word retaining its original accent (whether one of the accents is "primary" or "first among equals" or "more equal than others" is not clearThe English pronunciation of "rucksack" as either ˈrəkˌsak or ˈroŏkˌsak is not of much help.).
Monosyllabic words are not always accented; a typical example of unaccented monosyllable is the article ("the", "a(n)" in English), which is considered a proclitic and is pronounced together with the next word as one(in Greek, in addition to "proclitics", there are also "enclitics", that are pronounced together with the previous word as oneEnglish also has enclitics, but those are not full words). Examples of accented monosyllables are the interrogative words, such as "who?" ("Who is he?") and "what?" ("What is it?"), as contrasted with the identically or similarly written relative pronouns "who" ("The man who knew too much") and "that" ("The book that I gave you") (cf. also "¿qué?|What?"[SPA] and "que|that"[SPA]).
As already discussed, each syllable comprises exactly one vowel (or diphthong). Since it is the most prominent (better sounded) part of the syllable, the accent is associated with the accented syllable's vowel. When the accented syllable's "vowel" is actually a diphthong, only one of the diphthong's constituent vowels is emphasised or stressed, the other being much less prominant, shorter and less "full" (see next paragraph). When the stress is on the first constituent vowel, the diphthong is known as "falling diphthong" (almost all diphthongs in English), whereas a "rising diphthong" has its second constituent vowel accented (e.g., "bien|well"[SPA]).
Linguists define other kinds of accent, such as "pitch accent", "qualitative accent" and "quantitative accent". The former seems to relate to the syllable being pronounced with a different "pitch" or "intonation", like the musical notes and is allegedly attested in languages such as Swedish, Serbian and Slovenian. However, I have yet to hear a Swedish, Serbian or Slovenian speaker (colleague or friend) to speak with a musical accent, unless they are singing of course! The only cases where I can identify an accent as involving a higher pitch are the special cases of interrogation (cf. "You go home" and "You go home?") and exclamation ("Really!"), but this accent characterises the sentence rather than the word (in other words, the word is not always pronounced with a pitch accent, whereas dynamic accent is universal) and is, oddly enough, linguistically considered to represent stress! I also find the Irish or Scottish pronunciation of English quite "musical", but the respective languages are not listed as pitch-accent languages. So, until I reach the degree of sophistication (or illusion) of the modern linguists, I do not intend to waste more ink (rather keystrokes and bytes) to the pitch accent, which is, in any case, alien to Greek. As for the latter two kinds of accent, those relate to pronounce the vowels "more clearly or fully" (qualitative) or for a longer time (quantitative) and are usually by-products of the dynamic accent and the human tendency to speak will the least effort: when a vowel is unaccented (given lesser importance), humans tend to pronounce it, so to say, "halfheartedly"; on the other hand, dynamic accent "forces" the speaker to give more importance to the accented vowel and, since that has to be louder, it is also perceived as "longer" and "fuller". This phenomenon is also attested in some "uneducated" Greek pronunciations, where unaccented [e] and [o] are reduced to shorter, less clear sounds that resemble [i] and [u] respectively, while unaccented [i] and [u] are reduced to (almost) nothing.
There is also no need to refer to the "pitch" of tone languages, like Chinese, where it is not clear why the "tone" is considered a property of the word and not of the vowel, like voicing is for consonants (it does, after all, result in the creation of new phonemes, as evidenced by the minimal pairs that the various "ma"s represent).
Different words express different kinds of concepts (entities, actions, properties, etc.). The main word categories can be considered to be:
| Category | Concept Expressed |
|---|---|
| noun | Entity (abstract or concrete) |
| verb | Action performed by or to a noun |
| adjective | Property of a noun |
| adverb | Property of any other word but a noun |
The former two (noun and verb) are "standalone words" and the latter two (adjective, adverb) are "dependent words", since they need other words (e.g., noun for the adjective) to complete their meaning, although this might sometimes be implicit (cf. "the rich|[people]"). There are other word categories (articles, pronouns, participles, prepositions, conjunctions, interjections), but since these are language-dependent, they will be discussed for Greek in their respective section.
Often, words of a category conform to one or more patterns indicative of the category, for example German (infinitives of) verbs always end in "-(e)n" (cf. "singen|to sing"[GER], "liefern|to provide/deliver"[GER], etc) and a word's category can be identified (at least partly) by its form. This is not so in English, where the same (form of a) word may belong to more than one category according to the context or syntax (cf. the verbification "to google"Interestingly, the corresponding German verb is googeln! from the identical name/noun "google" or the ambiguity of the expression "time flies", where each word can be either a nountime=the indefinite continued progress of existence; flies=nasty flying insects or a verbtime=measure the time taken by; flies=travels through the air).
Words combine to build "sentences". While individual words express elementary concepts, sentences describe how these elementary concepts interact with each other, to convey the desired message from one human to the other.
The rules that define how words are put together to form sentences are known as "syntax".
The core of each sentence is a verb that expresses the aforementioned interaction, even if it is only implied (cf. "Who gave you this? Peter|[gave me this]"). The noun that performs the action of the verb is called "subject" (cf. "I see"). Things are more complicated in the case of passive voice, where the verb expresses (from the point of view of the receiver of the action) an action that is received by the subject (cf. "I am seen"). In languages like English, French and German the subject is almost always explicitly indicated (cf. "I see", "ich sehe"[GER], "je vois"[FRA]; one of the cases where it is omitted is the imperative, e.g., "go home!", since it always refers to the second person, "you|French and German distinguish the imperative also for number, that is they have different imperative forms for second person singular, thou, and second person plural, ye|300"). But in languages with full conjugation, it is not necessary to indicate the object, when this is understood from the verb's person and number (cf. "veo|[yo]"[SPA], "vedo|[io]"[ITA]).
When the action of the verb is directed to a noun other than the subject the verb is called "transitive", otherwise "intransitive". The noun that receives the action of a transitive verb is called "object". A curious case are the "reflexive" verbs, where the action performer and receiver are the same, but in some languages it appears both as subject and object (cf. "ich frage mich"[GER], "je me demande"[FRA] for "I ask myself/I wonder"; also the erroneous English expression "we see us" used by some Germans as a translation of "wir sehen uns"[GER] instead of the correct "see you").
Some transitive verbs allow two objects, one being the actual receiver of the action and called "direct object", the other being an indirect participant in the action and called "indirect object". In the sentence "I give the book to you", "I" is the subject, "the book" is the direct object and "to you" is the indirect object, since the act of "giving" is performed on "the book" and "you" are a beneficiary of the act of "giving". Some languages, like German, indicate the indirect and direct objects in different inflected forms, in particular different cases (the above example in German would be "ich gebe dir|dative case, indirect object das Buch|accusative case, direct object"[GER]). Other languages, like Spanish, do not have a clear distinction between indirect and direct objects, but rather between personal and impersonal objects (cf. "veo a los niños|lit.: I see to the children"[SPA], note the use of a prepositional expression for the direct object, because that is a person). English is rather... confused, as indicated by the sentences "I gave her the book" and "I gave her to her husband", wherein the same word, "her", in the same position is the indirect object in the first example and the direct object in the second.
English relies on word position to indicate whether a noun is a subject or an object of a verb, as subjects precede their associated verbs and objects follow them (one exception, in addition to the imperative discussed above, is inversion, such as "Seldom are girls hyperactive"). So, it can be fairly safely said that the word order in most English sentences is SVO, wherein S is the subject, V is the verb and O is the/any object. Thus, the sentence "the mouse ate the cat" always signifies what is considered "impossible" or "illogical". Languages that have complete declension do not need a fixed syntactical order for indicating a noun's function, so (in theory) they have a free(r) word order.So, in the cat-and-mouse example, it would be possible to retain the word order, the mouse being in the accusative case and the cat in the nominative case and the sentence would make the sense one expects. But, in practice, there are at least some rules for word order in certain cases, e.g., pronoun objects immediately precede or follow the verb (oddly enough, standard German, which belongs to this group, imposes an inexplicably strict sentence structure, with the verb always at the second position in main clauses and at the last position in subordinate clauses). However, it would be incorrect to classify a fully inflectional language (including German) as a SVO (or any other order) language, unless it has a very narrow-minded syntax.This might be the case with Latin, which has full inflection, but is classified as a SOV language.
In some cases, embedded sentences can be identified within a (complex) sentence, such as "I convinced him to hand over his gun", "I know (that) he did it", "I gave it to the guard who stood at the entrance", "forgiving your enemies is not easy". The underlined parts have the normal structure of a sentence, with a verb (either finite or non-finite), an object and a subject (at least implied in the case of the non-finite verbs of the first and fourth examples), but cannot exist alone. Such sentences are known as "subordinate/dependent/secondary clauses" and are always attached to a "main/independent/primary clause" (the remaining part of the examples above). Sometimes, the subject and/or object of a main clause may be replaced by a subordinate clause (cf. "I know that" vs "I know what you did last summer" and "he is guilty" vs "whoever knows these facts is guilty"). Usually, subordinate clauses are introduced by "conjunctions" (little words that link clauses or sentences, such as "that" in the second example above) or "relative pronouns" (words that refers to and clarify something already mentioned, such as "who" in the third example above and "that" in the sense of "which" or "who"). However, not all conjunctions introduce subordinate clauses. Some, like "and", "or", "but", merely link two main clauses together (e.g., "he told me the truth and (he) went home").
The nature of human language is primarily aural (and... oral). However, one problem with spoken language is that, to put it in... classical terms, "verba volant|lit.: (spoken) words fly"[LAT] and a need exists to preserve language through time or to "record it". Until the invention of the phonograph in the 19th century, it was not possible to record language in its aural form, so the need was met by the employment of alternative encoding systems that made use of materials with more permanent properties than air. Thus, writing was developed, which, as already seen, involves the creation of visual markings on physical (tangible) objects.
In principle, writing does not need to be related to speech. It represents just another way of mapping the abstract concepts one wants to communicate to symbols (visual markings) that will be decoded by the communication party to (hopefully) the original abstract concept (assuming that that one is aware of the mapping convention used to produce the writing). In practice, however, since well-organised speech preceded well-organised writing by many centuries (even millenia), writing has followed speech rather closely. Thus, writing usually conforms to one or another of the aforementioned aspects of spoken language.
In general, every writing system employs a number of pictorial symbols (the "visual markings" mentioned above) for representing some aspect of a spoken language. When discussing speech in the previous section, we started from its elementary forms (phonemes) and progressively moved towards its more synthetic forms (sentences). It is fairly safe to claim that writing developed in the opposite direction, namely from simpler forms, where entire sentences are represented by a single illustration, to more complex forms, where (groups of) elementary sounds are represented each with its own illustration (or "character"). The presentation of writing systems herein below will follow this "evolution" from representation of entire sentences ("phraseographic writing"), to words ("lexigraphic writing"), to syllables ("syllabographic writing"), to phonemes ("phthongographic writing").All three terms are coined by me for convenience; none of them is established in the linguistic circles.
As
an example of early representation of "sentences" one may consider
drawings of different scenes, such as cave
paintings.
While this is not "writing" in the official sense, it does,
nevertheless, record and convey a message that would need (more than) a
full sentence to express using speech.  Another
(non-historical) example
of an illustration that encodes the meaning of a sentence is the
drawings of the... literarily-challenged, when they need to
remember something. For example, when my grandmother (who, in the hard
times
that she grew up, never learned to read and write properly) wanted to
make a note of the doctor's instruction to "take two pills after each
meal", she came up with the drawing to the right. Similar
"sentence-writings" are encountered in everyday life, including traffic signs
that represent sentences, such as
"watch out, the road is slippery", etc.
Another
(non-historical) example
of an illustration that encodes the meaning of a sentence is the
drawings of the... literarily-challenged, when they need to
remember something. For example, when my grandmother (who, in the hard
times
that she grew up, never learned to read and write properly) wanted to
make a note of the doctor's instruction to "take two pills after each
meal", she came up with the drawing to the right. Similar
"sentence-writings" are encountered in everyday life, including traffic signs
that represent sentences, such as
"watch out, the road is slippery", etc.
All these drawings convey meaning in a language-independent
way.
All that one needs to know is the special meaning assigned to each
drawing, which, in most cases, is closely associated with the drawing's
illustration and can be guessed when the drawing is considered in an
appropriate context (for example, the above illustration will be
probably assigned the aforementioned meaning if, e.g., drawn on a box
of pills, but in a different context, e.g., in a shooting range, it
might be interpreted differently, for example... "shoot pregnant women
twice!").
Instead of encoding entire
sentences with a single drawing it is also possible to use a pictorial
symbol for representing the words of a spoken sentence. This is much
more than depicting a scene (such as hunting), where the various actors
are clearly and distinctly visible. In representing the words of a
sentence, one has to also take care of all parts of a sentence, not
only of the nouns. A fairly primitive example of an
attempt to write a sentence by depicting its words is the illustration
below. Here, the first image may stand for the notions of
"justice", "judging", "judge", "fair", "fairness", etc. The second may
represent "death", "dying", "causing to die" and the third "science",
"scientist", "experiment", "experimenting", "knowledge", "experience"
etc. This illustration may, therefore, represent any of the sentences:

In absence of a pre-agreed and predefined syntax, it is impossible to know for sure which word each image represents and what its role in the sentence is. This kind of representation is, therefore, inherently ambiguous.
Another disadvantage of lexigraphic writing is the sheer volume of required symbols, since even the simplest of languages comprise a few thousands of words in everyday use.
An example of lexigraphy in everyday life is the representation of the cardinal numbers by the symbols 1, 2, 3, etc.
As already seen, pictorial representation of a language suffers from an inherent ambiguity and a need to be refined, in order to express additional (to semantics) aspects of a language, such as morphology and syntax. Instead of inventing a whole new language encoding from scratch, it is wiser to rely on and reflect the established language model, speech. The question of how to represent speech has been addressed by breaking down spoken utterances (words and sentences) into a number of elementary sounds. Since the building blocks of speech are primarily the syllables, the first attempts to represent speech involved devising a symbol for every possible syllable of a particular language. From the syllable model defined above, it is evident that the number of syllables may be extremely large (if C and C represent none to three consonants each, and assuming as many as 20 vowels/diphthongs and 30 consonants, which is normal for a language like English, there are as many as a few million possible syllables). However, for a well-behaved language that avoids consonant clusters and diphthongs this number is much smaller. Thus, in languages that have a simpler syllable structure, such as CV (as is the case in Japanese), and a more reasonable number of sounds, say the 5 basic vowels and no more than 20 consonants, there are no more than 100 possible syllables and the advantages of representing the possible syllables over representing all possible words are evident (of course, in monosyllabic languages, such as Chinese, syllabic writing and word writing are equivalent). The set of characters of a syllabographic writing systems is known as "syllabaries".
While syllabographic writing is a significant improvements over the ambiguous and voluminous lexigraphic writing, the number of characters that need to be learned is still high and learning is tedious. Moreover, in practise, similarly sounding syllables, like [ka] and [ko], are not represented by similar charactersOf course, the use of dissimilar characters for similar phonemes is also found in alphabetic scripts, as is evident from b and p, t and d, etc., as seen in, e.g. the Cypriot Syllabary. A development that can reduce the number of characters can be based on the representation of the syllables (rather C(V) clusters) that share the same consonant and any (or no) vowel by the same character. This is, essentially, equivalent to only indicating the consonants and reduces the number of characters to the number of the language's consonants, but also introduces some ambiguity about the syllable that a vowel represents (essentially, about the omitted vowels). The resulting ambiguity may be mitigated by the structure of the language, in particular if vowels are not important for word semantics. This was allegedly the case with ancient Semitic languages, which first developed a reduced set of characters, allegedly lacking any vowel representation.However, they did include characters for at least the so-called semivowels [i/j] and [u/w].
If this theory holds water, the writing system of the ancient Western Semitic languages was only partially phthongographic and the representation of the spoken language was incomplete (the two most prominent modern Semitic scripts, Arabic and Hebrew, make use of special diacritics to indicate the vowels accompanying each written consonant, thus rendering the script rather syllabographic). As a consequence, the invention of full phthongographic (also known as "alphabetic") writing is credited to the ancient Greeks before the 8th century BC. In accordance with the most predominant theory, some Greeks (possibly the Ionians) adopted the Phoenician variation of the Western Semitic alphabet and indicated the vowels (notably [a], [e], [o]) with Phoenician letters that did not have a consonant equivalent in Greek. Thus, the Greeks were (allegedly) able to represent all sounds that make up a word and come as close to recording sound as possible without Edison's contraption.
The simplicity (in terms of number and form of its characters) and the completeness (in terms of sound representation) of the alphabet has rendered it the most widespread form of writing. Since it is also the writing system of Greek, some of its aspects will be further examined herein below.
Unlike the highly illustrative
nature of former scripts, especially those used for phraseographic or
lexigraphic writing, the alphabet belongs to the family of the
so-called "linear
scripts", which is
essentially an interesting by-product of
pictorial representation.  Because
not everyone is inclined to produce sophisticated drawings with high
accuracy, those tend to be standardised by simple lines and may evolve
to depict shapes that have little to do with the intended original, as
illustrated on the left for a drawing of a house that may end up being
represented by a mirrored-b symbol (which, by the way, may seem more
plausible than it actually is, considering that the meaning of the
corresponding letter's name, "beth", is... "house"!). Linear characters
may be as simple as the (capital) letters of the alphabet to as complex
as the Chinese
characters. Essentially, all
present writing systems are linear, pictography
being confined to special uses, such
as traffic signs, and to extinct
writing systems.
Because
not everyone is inclined to produce sophisticated drawings with high
accuracy, those tend to be standardised by simple lines and may evolve
to depict shapes that have little to do with the intended original, as
illustrated on the left for a drawing of a house that may end up being
represented by a mirrored-b symbol (which, by the way, may seem more
plausible than it actually is, considering that the meaning of the
corresponding letter's name, "beth", is... "house"!). Linear characters
may be as simple as the (capital) letters of the alphabet to as complex
as the Chinese
characters. Essentially, all
present writing systems are linear, pictography
being confined to special uses, such
as traffic signs, and to extinct
writing systems.
As already seen, the phthongographic writing system that is known as the "Alphabet" (from the names of the first two letters in Greek, "άλφα" and "βήτα" or "alpha" and "beta" in Latin transliteration) is a West-Semitic invention, at least as far as the form of the letters is concerned (the original shape of the letters of the early Greek alphabets was almost identical to that of the Phoenician letters and the names of the Greek letters sound very much like those of the Phoenician letters without having any obvious Greek etymology), and its use for representing all uttered sounds of a spoken words is an innovation that was most probably introduced by the GreeksEven if the Semitic scripts did include vowels, word representation must have been at least... erratic, as attested by written words, such as MLK and YHWH. shortly before or after the start of the last millenium (11th-8th century) BC.
In the next couple of millennia (11th century BC-9th century AD), the Greek alphabet spawned a number of other language-specific alphabets in the Eastern-Mediterranean/Black-Sea basinThe Canaanite scripts, especially Phoenician and its derivative Aramaic, also spawned a number of Asiatic scripts, such as Paleo-Hebrew, Brahmic and Arabic, but none of those can be clearly classified as pure alphabet., notably the various Italic scripts (8thcentury BC), Coptic alphabet of Egypt (3rd century AD), the Gothic alphabet of Ulfilas (4th century AD), the Armenian and possibly Georgian alphabets (5th century AD) and the first Slavic alphabets (9th century AD). Of the Italic scripts, which were based on the Western variation of the Greek alphabet, Latin was the only alphabet that survived. The development of all other alphabets mentioned above was the result of the influence of the prestigious Greek-speaking Eastern Roman Empire and involved the reuse of some letters of the Greek alphabet, as well as the introduction of new letters that represented sounds not present in Greek.
On the other side of the Mediterranean, after the dissolution of the Latin-speaking Western Roman Empire, a diverse number of peoples that occupied the lands of or around it adopted the Latin alphabet, essentially unmodified, for writing languages considerably different from Latin (originally Gaelic and Germanic, but subsequently also Baltic, Slavic, Finno-Ugric etc.). The introduction of new letters was minimalNotably, the Germanic innovations of distinguishing J from I and V/W from U and the adoption of some Greek letters, like K, Y, Z., the use of the same letters for representing different sounds was maximalcf. the Italian, French, Spanish, German, Slavic and Turkish pronunciations of C. and the creation of new letters was circumvented by the use of diacritics on existing letters and digraphs or trigraphs. Thus, the five-vowel Latin alphabet was used for languages with as many as a couple dozen vowels, the extra sounds being disguised as adorned characterscf. é, è, ê, ë, à, å, â, ă, etc. or "allophones" of basic Latin characters pronounced differentlycf. the English and Portuguese pronunciations of A. or according to their contextcf. the four different pronunciations of French E in "appeler"[FRA], "appele"[FRA]. or combinationcf. the effect of French U in "sous"[FRA], "ceux"[FRA], "sœur"[FRA], "brun"[FRA] with other characters. This reluctance to improvise instead of adopting an established writing system "as is" (unlike the ingenuity of Late Egyptians, Eastern Germans, Armenians, Caucasians and Eastern Slavs) created the illusion that a large number of diverse languages (including Indo-European languages, such as French, German, Gaelic and Polish, but also many languages not related to Latin, such as Basque, Finnish, Hungarian, Turkish, Vietnamese, Tagalog, etc.) are using the same "Latin alphabet", whereas the truth is that the letters of the original Latin alphabet are (ab)used to represent sounds considerably different from the ones that they were initially designed for and the same characters are pronounced in as many different ways, as there are languages that use the "Latin alphabet". The fact that these languages do not use the same alphabet, but merely letters of the same shape, is evident from the question "How do you pronounce your name?", when the name is already written with "Latin characters", and the uncertainty about the language behind some words that are spelled the same, but have different pronunciations and meanings in different languages (one example being the word "Quelle").
In order to remedy this inconsistency, some attempts were made to develop a "Universal Alphabet" the letters of which would be pronounced the same way in every language. The instigators of the most famous attempt, the International Phonetic Alphabet (IPA), were aptly language teachers of the two most wicked (in terms of consistency between writing and speech) Latin-alphabet-based languages, English and French. After more than a century of expansion to include the sounds of ever more languages, its present size is daunting: more than 100 distinct letters (five times the size of the original Latin alphabet, upon which it is supposedly based) and numerous modifying marks (such as diacritics). The disadvantages of a "universal alphabet" are also evident: what in one language are considered allophones of the same phoneme, in another they may be separate phonemes; furthermore, the extremely fine quantisation of the IPA, especially that of the vowels, may be meaningless for languages that have considerably fewer sounds than those represented by the IPA, as several of the IPA symbols may fall within the area of a single symbol of this particular language. However, despite its disadvantages, the IPA is the best writing system we have for easily describing the sounds of a language.
One would expect that the alphabet would provide a straightforward way to record a spoken language. In practice, however, there is often some inconsistency between the written and the spoken forms, as is best confirmed by the English spelling. There are two kinds of inconsistencies: in reading, when the same letter is pronounced in different ways, and in writing, when the same sound is represented by different letters or combinations of letters.
Most languages have a fixed way of pronouncing their letters, even though this might sometimes necessitate identifying digraphs or trigraphs (that should be pronounced as monophthongs) or inspecting a letter's context (surrounding letters), in order to use one of its alternative pronunciations. Thus, for languages like Spanish or German, the exact sounds of the spoken language can almost alwaysOne example of inconsistent reading is the diverging German pronunciation of IE in Wien and Wiese vs. Italien and Brienner. be deduced from its written form by applying a set of certain reading rules. One may refer to those languages as "what-you-see-is-what-you-read" or "WYSIWYR". English (like FrenchAt least as far as the pronunciation of some letters at the end of words is concerned.) is certainly not a WYSIWYR language, as confirmed by the uncertainty of whether the expression "I read the book" refers to an action of the past|[rɛd] or the present|[riːd]. Much higher is the number of languages that do not consistently represent the same sound with the same letter or combination of letters. Thus, words that sound exactly the same may be spelled differently.cf. rain, rein, reign in English. The correct way of using the letters of a language to represent its sounds is called "orthography".
The reasons for the divergence between alphabetic writing and speech are usually thought to be etymology and sound shifts within a language. This theory assumes that, at some point in history, an alphabet was used to perfectly represent the sounds of a language; then, the natural process of sound change caused phonemic mergers, wherein originally distinct sounds (represented by different letters) were pronounced identically, and phonemic splits, wherein the same letters (originally pronounced the same everywhere) received different pronunciations according to their context; as a result of habit or respect for the language of the "good ole days", the orthography was maintained and writing reflected the historical spelling rather than the actual phonology of the language. While this theory is plausible for the fairly recent past (the sound shifts of the Germanic languages in the last five centuries having been extensively studied), the further back we go into the history of alphabetic writing, the less sure we can be about the spelling conventions used, namely we cannot know how the alphabet was used to "record" speech. As already seen, before being fully phthongographic, alphabetic writing was either partially phthongographic (consonantal) or inconsistently approximate; despite the subsequent (introduction and) representation of vowels, it is quite improbable that the ancient Greeks (the first users of a full alphabet) suddenly grasped all complexities of phonemic representation, something that eluded the users of previous writing systems. So, early alphabetic scripts are unlikely to have been perfectly phthongographic and they must have comprised a certain degree of approximate representation. Since alphabetic writing does not always preserve a language's phonology (although it tries to follow it as closely as possible) and since we do not have any recordings of spoken languages before the invention of the phonograph, one cannot be sure whether alternative spellings that suddenly appear at some point in history correspond to revised spelling rules or to new pronunciations. Another point to bear in mind is that the alphabet has been borrowed from one language to another (Phoenician → Greek → Etruscan → Latin etc.); thus, every language (at least from Greek on) initially uses a writing system that was not designed for it and some spelling conventions are, therefore, necessary for adapting one language's alphabet to another. This situation is exemplified by the adaptation of the five-vowel Latin alphabet to languages that have more than five vowels, by means of diacriticscf. French é, è, ê, etc., but most frequently digraphscf. Dutch ie, eu, oe, etc. (perhaps to indicate that the intended sound lies between or is a "combination" of the two sounds); it would, therefore, be incorrect to conclude that, e.g., a digraph used to originally represent a different sound that subsequently shifted to its present value.For example, it appears that the German vowels ä, ö, ü, that were originally spelled ae, oe, ue, were never pronounced as diphthongs.
The uncertainty about the correct spelling of a word is present even in languages that have underwent spelling reforms and have severed the ties with their ancestor languages, such as Spanishcf. the use of (mute) H and the spelling with J vs. G and Y vs. LL. This is because the adoption of a purely phthongographic writing system is an arduous process that has to build on past experience and to be designed carefully (usually by a central authority) starting from scratch (disregarding any previous writing system). Thus, only few languages have a one-to-one correspondence between spoken sounds and written letters, notably those that adopted their alphabet quite recently, such as TurkishNevertheless, as hard as I try to pronounce some words the way I read them, I cannot match the pronunciation of my Turkish friends and colleagues for some words, such as "iyiyim"[TUR] and "oğlu"[TUR]..
|
|
|
|
|

